On FastGAN
Introduction
Are GANs the perfect solution for unconditional image generation? What about the problem of training instability and high computational cost? In the paper "Towards Faster and Stabilized GAN Training for High-Fidelity Few Shot Image Synthesis" (Liu et al., 2021) [1], a group of researchers addresses this issue by proposing some modifications to the GAN architecture. In this blog post, I want to focus on the paper and try to explain the main idea.
Quick recap on GANs
GAN is an acronym for Generative Adversarial Networks. It is a joint neural network consisting of two sub-networks: the Generator network and the Discriminator network. From a probabilistic perspective, we can think of the Generator network as a function that, given a random set of numbers (noise), outputs data that is likely to come from the modeled distribution.
The Discriminator is a network that, given real images and fake images (generated by the Generator) tries to distinguish between them, outputs a probability, of how likely it is that an image is real or fake. In short, the Generator wants to fool the Discriminator to assigning a high probability to the fake images, and the Discriminator,on the other hand, wants to assign a low probability to the fake images. That is why the term adversarial is used here, since the two networks have opposing goals.

Imagine we have a distrubution of images by some famous artist for example, Van Gogh. We want to produce images that look as if they were painted by Van Gogh. From a technical point of view, we are given the task of sampling. We want to sample an image. from the distribution of images painted by Van Gogh. The issue is that we do not have the explicit distribution of these images. All we have are points (images) sampled from this distrubution. In the case of GANs our best bet is to implicitly model this distrubution i.e we are not producing parameters of such a distribution but rather points (images) that are likely to come from this distribution.
Why are GANs difficult to train?
All of this sounds very promising, and it seems that GANs are a perfect solution for uncoditional image generation. However, GANs suffer from one major problem. The problem is the so called curse of dimensionality. The two networks operate on a high dimensional space of images (pixel space). This makes the networks very large since the number of weights has to correspond with the resolution of the image. Imagine an image of 512x512 pixels, that we are trying to to produce from a set of 64 normally distributed numbers (noise). Such a network that uses convulutional layers would have a huge number of weights (millions). The number of layers and the number of weights grow with the resolution of the image. This makes the training of these networks highly unstable since the gradient has a very low impact on the weights in the first layers of the network.
This main problem gives rise to a number of other problems, including: mode collapse, high computational cost, and makes the entire GAN game highly unintuitive and most of the times luck based.
How to improve GAN training?
Liu et al. propose two main modifications to the GAN architecture that I want to write about [1]. The first modification is the use of a method called "skip layer channel-wise exicitation". The overall idea behind the method helps to address the problem of gradient flow in the network. The concept is simple: we connect the output of a convolutional layer via a skip-block preserving (only the channel dimension) with an output of a layer further down in the network and pass it as input to the next layer.
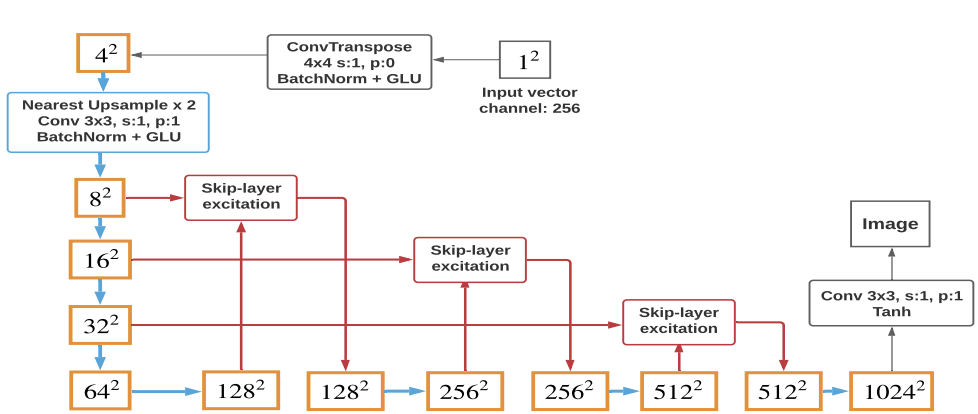
The second modification is adding decoders to the Discriminator network. The idea is that Discriminator is also being actively trained to decode intermediate feature maps to parts of the image, in hope of combating mode collapse. This is because the same feature maps are used for both decoding and discriminating. So the Discriminator is actively challenged to improve its decoding ability, and add more powerful gradient to the Generator.
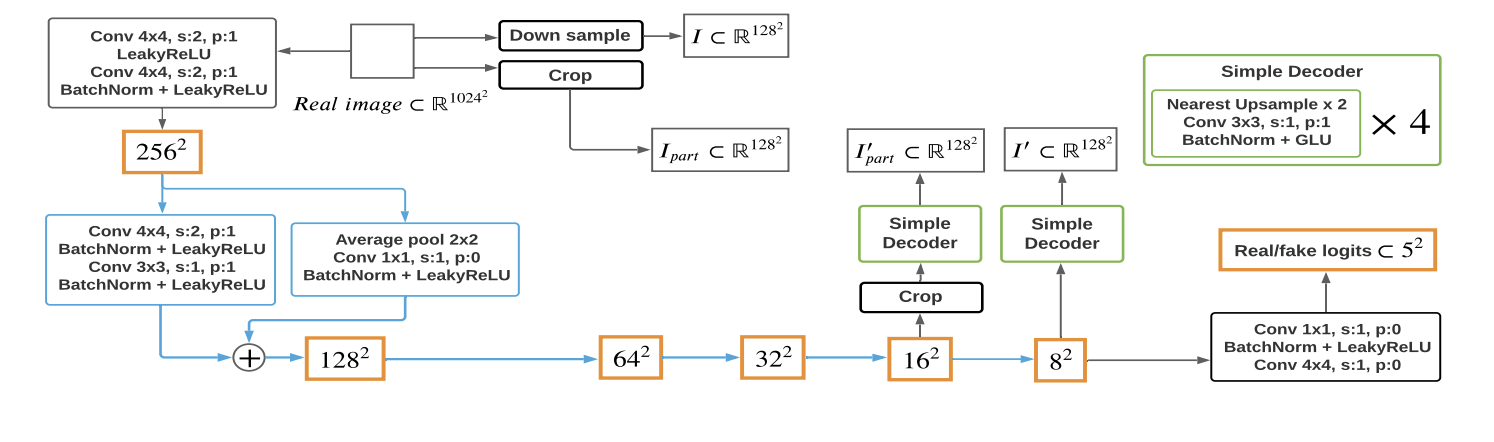
On top of the architecture based modifications, the authors also added a crucial add-on to the training procedure. To combat mode-collapse, which arises when the training dataset is low in samples, they added
Differential Augemntation [2]. This is a technique that can be widely used in any generative image generation problem. The concept is suprisingly simple it adds new images to the distribution of the images by cropping or adding noise to the images, by this the Discriminator is forced to learn more and it cannot just remember a good sample from the data distrubution. In short Differential Augemntation augemnts the data distribution by adding probable outliers to this distribution.Results?
Yes but how does FastGAN work in practice? Although the proposed architecture is still quite complex and training process for 512x512 images still takes quite a long time ~15 hours using Google Colab with the free GPU. The results are quite impressive after training on the VanGogh dataset we get quality samples. These samples differ from what you can obtain using diffusion based architectures; they seem more art-like and less artificial. (click on the video to see the code)
Improving FastGAN with class labels and decoders?
Perhaps improving the convergence of the Fast GAN is possible by adding additional decodings to the disciminator. This is a question that I am currently exploring.
Altough my initial findings have not been conclusive the question is still worth exploring( see my initial paper).
Another interesting idea is to use class labels to improve the convergence of the Fast GAN, this approach is also one to be explored. Another question worth asking is: what exactly is the use of GANs in the context of diffusion based models? Perhaps the two approaches can be combined to produce even better results.
Refernces
[1] Liu, B., Yinhe, Z., Song, K., & Elgammal, A. (2021). Towards Faster and Stabilized GAN Training For High-Fidelity Few Shot Image Synthesis. arXiv preprint arXiv:2101.04775.
[2] Zhao, S., Zhijian, L., Ji, L., Jun-Yan, Z., & Song, H. (2021). Differentiable Augmentation for Data-Efficient GAN Training. arXiv preprint arXiv:2006.10738.