Multimodal Embeddings in Image Retrieval
Introduction
In this article, we will explain what multimodal embeddings are and how they can be used for image retrieval.
What is Multimodal Image Retrieval?
The goal of image retrieval is to retrieve the most relevant images to the query image. Imagine we are looking for more pictures depicting a specific geographical location, such as the Gullfoss waterfall in Iceland.
In a standard image retrieval system, our query will be encoded into high-dimensional vectors using image encoders such as ResNet, ViT, etc., and using some similarity metric (e.g., cosine similarity), the most relevant images from a large database of candidate images will be retrieved.
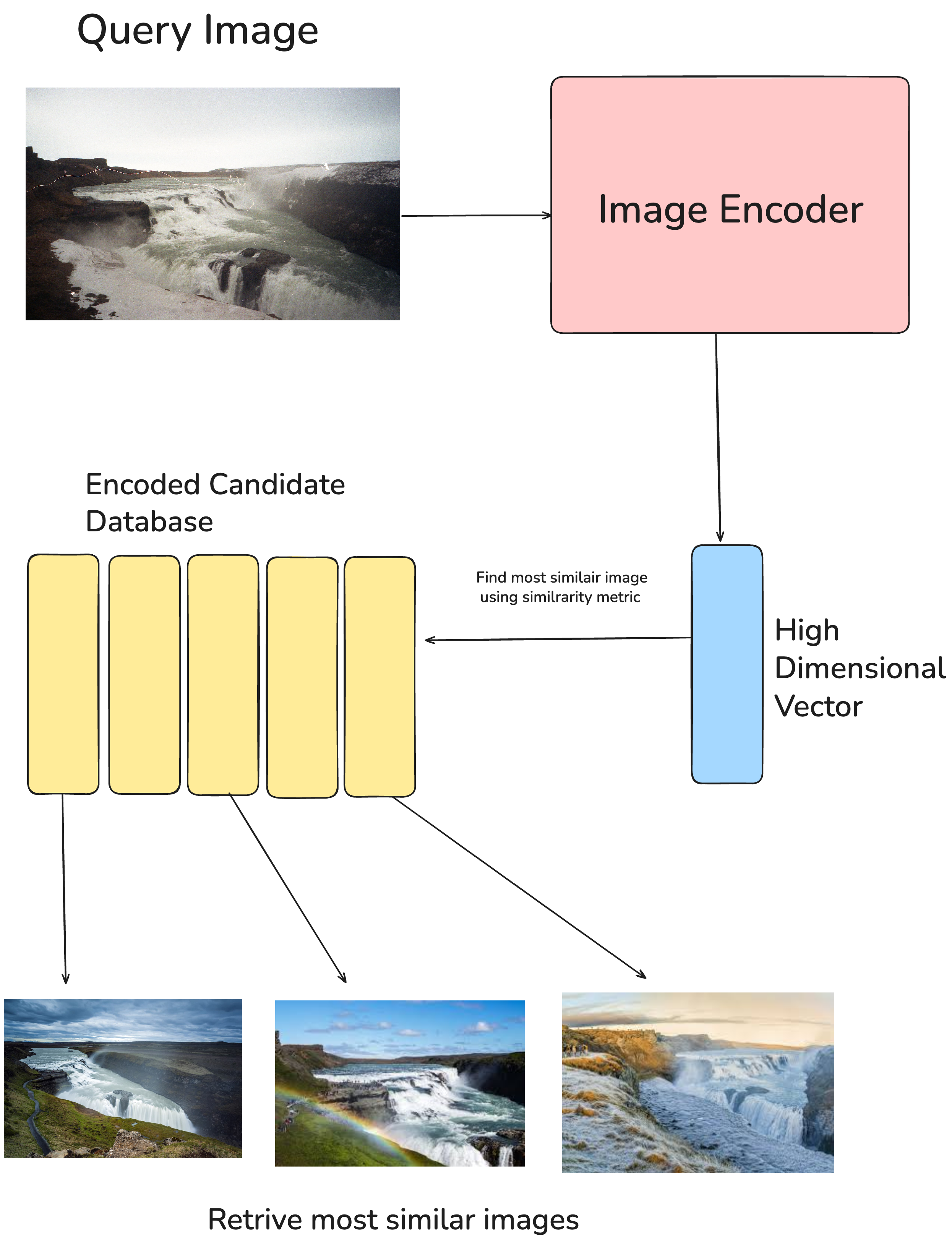
In a multimodal image retrieval system, the goal remains the same, but the query is a combination of the image and some other modality such as text, image metadata, etc.
In our scenario, we'll be working with images taken from the ISS (International Space Station). The goal of our image retrieval system is to retrieve relevant candidate images for our queries, where "relevant" means there is a non-zero overlap between the query and the retrieved images. Briefly, there are three sources of data:
- 1. The query image taken from the ISS
- 2. The candidate images taken by the Sentinel-2 satellite in the year 2021
- 3. The image metadata (nadir) for both the query and candidate images
The nadir is the point on Earth's surface directly below the satellite. It is useful metadata for the ISS images, as knowing it can provide a rough estimation of where the image was taken (we can be sure that the image is within ~2500km of the nadir point). The picture below helps illustrate this concept better.
The question remains, however: how to use the metadata to improve retrieval performance? We've opted for a simple approach partially inspired by the recent CVPR paper by Dhakal et al. [1] and the GeoCLIP paper [2]. We use a pretrained DINOv2 foundation model as the image encoder combined with a SALAD aggregator to improve the embeddings' performance. For the metadata encoder, we pass the nadir coordinates (latitude, longitude) through a combination of Fourier Features and standard MLP layers to obtain a high-dimensional embedding. After having both the image and metadata embeddings, we simply concatenate them and use this as our final multimodal embedding. We train using a multi-similarity loss on the concatenated embeddings. The picture below illustrates the architecture better.
Experimental Setup
We performed two experiments to prove whether multimodal embeddings improve retrieval performance. In the first experiment, no metadata is used—only the image embeddings are used for retrieval. In the second experiment, we use the image embeddings concatenated with the metadata embeddings for both the query and candidate images.
Results
The results are reported on each of the evaluation datasets (Alps, Texas, Toshka Lakes, Amazon, Napa, Gobi) using the standard Recall@K metric. It's worth noting that all 161,496 candidate images are used for retrieval, making the task more challenging. Below is the coverage of the query and candidate images used for retrieval.
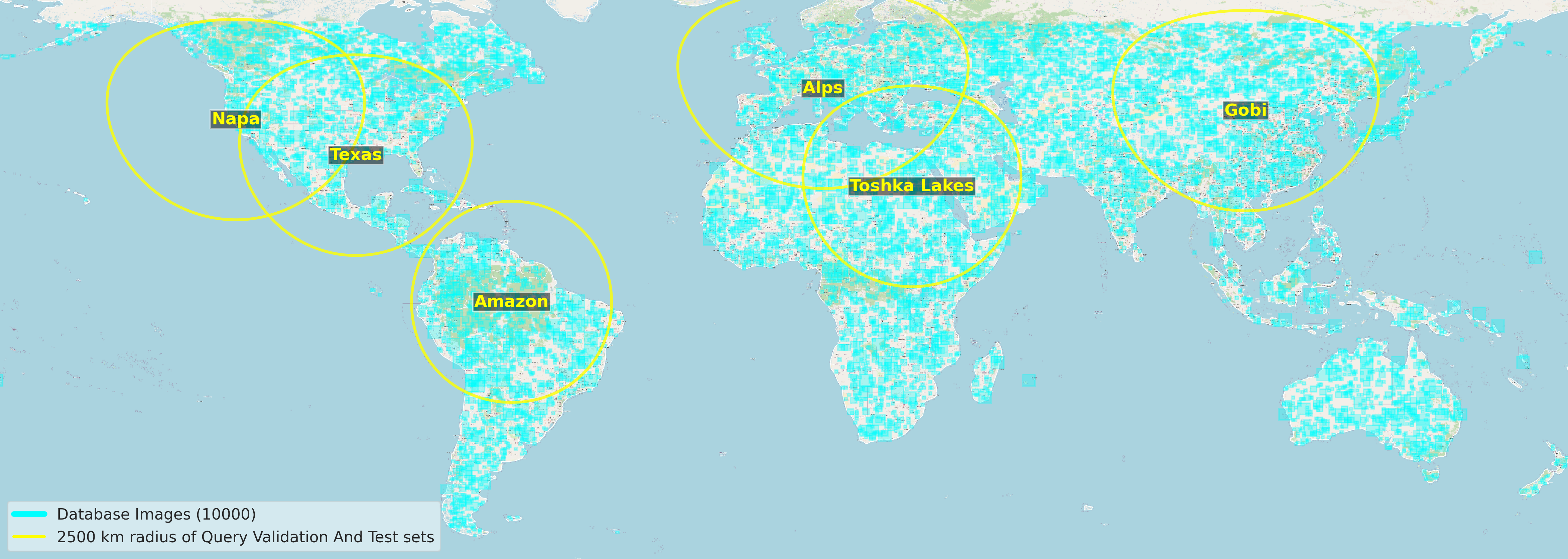
Image + Coordinate Embeddings
| Dataset | Number of Queries | Number of Database Images | R@1 | R@5 | R@100 |
|---|---|---|---|---|---|
| Alps | 2394 | 161496 | 80.8 | 89.7 | 97.3 |
| Texas | 6143 | 161496 | 82.1 | 89.0 | 96.1 |
| Toshka Lakes | 2164 | 161496 | 90.6 | 95.1 | 98.7 |
| Amazon | 682 | 161496 | 77.9 | 85.5 | 93.5 |
| Napa | 3569 | 161496 | 82.5 | 88.9 | 96.4 |
| Gobi | 726 | 161496 | 74.4 | 87.1 | 97.0 |
Only Image Embeddings
| Dataset | Number of Queries | Number of Database Images | R@1 | R@5 | R@100 |
|---|---|---|---|---|---|
| Alps | 2394 | 161496 | 78.8 | 87.2 | 96.4 |
| Texas | 6143 | 161496 | 80.1 | 86.8 | 95.1 |
| Toshka Lakes | 2164 | 161496 | 90.1 | 94.3 | 98.4 |
| Amazon | 682 | 161496 | 73.5 | 82.3 | 91.6 |
| Napa | 3569 | 161496 | 80.6 | 87.4 | 95.2 |
| Gobi | 726 | 161496 | 74.7 | 85.3 | 96.0 |
Discussion
We observed on average a 2-3% increase in the Recall@K metric across all datasets when using multimodal embeddings. The most significant improvement was observed on the Amazon dataset, which may be due to the fact that the nadir coordinates provide better context for the image, as the Amazon rainforest is a large area and the images taken from the ISS may not have enough distinctive features to be easily retrievable using only image embeddings.
Future Work
We believe that image retrieval can see significant performance improvements when using multimodal embeddings. This article may be seen as a proof of concept—there are many ways to improve performance further.
References
[1] Dhakal, A., Sastry, S., Khanal, S., Ahmad, A., Xing, E., & Jacobs, N. (2025). RANGE: Retrieval Augmented Neural Fields for Multi-Resolution Geo-Embeddings. arXiv preprint arXiv:2502.19781.
[2] Vivanco, V., Nayak, G. K., & Shah, M. (2023). GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization. In Advances in Neural Information Processing Systems.
[3] Oquab, M., Darcet, T., Moutakanni, T., Vo, H. V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Howes, R., Huang, P.-Y., Xu, H., Sharma, V., Li, S.-W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., & Bojanowski, P. (2023). DINOv2: Learning Robust Visual Features without Supervision. arXiv preprint arXiv:2304.07193.
[4] Izquierdo, S., & Civera, J. (2024). Optimal Transport Aggregation for Visual Place Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Technical Details
All models were trained on a single NVIDIA H100 100GB GPU. We used the DINOv2-based model with register tokens and SALAD aggregator. The learning rate was set to 1e-4. The models were trained for 20 epochs with a batch size of 96. For more details, consult the GitHub repository here.